{kind=link}

| Tilmanns Corner - sed |
|---|
Quickstart:
--> Links
--> Apache log analyser
--> Mail addsfilter
--> Mail to HTML
--> Pine addresses to Vim
--> Callerid to Vbox
--> Indexhtml
--> diff(1) HTML beautifier
<-- Tilmanns Corner
<-- Mainpage
| Links |
|---|
SED links from the excellent FAQ from http://www.student.northpark.edu/pemente/sed/sedfaq.html
| Eric Pement | http://www.student.northpark.edu/pemente/sed/index.htm |
| Seders Grab Bag | http://spazioweb.inwind.it/seders/ |
| Sven Guckes | http://www.math.fu-berlin.de/~guckes/sed/ |
| Felix von Leitner | http://www.math.fu-berlin.de/~leitner/sed/ |
| Yiorgos Adamopoulos | http://www.dbnet.ece.ntua.gr/~george/sed/ |
| apache log analyser |
|---|
A very simple Weblog analyser, which extracts the search words from google and
altavista referrers, marking them with an a for altavista or G google.
Download here: sedlog.gz
Usage:
$ wget http://tibit.org/sedlog.gz $ gzip -d sedlog.gz $ chmod +x sedlog $ ./sedlog access.log | vim - |
| Mail addsfilter |
|---|
A sed script that I use as an incoming mail filter to get rid of the adds in some newsletters I am subscribed to. I don't had any bad side effect until now ;-) This is used in conjunction with procmail; below is a sample procmail entry:
# remove adds in billiger
/+-.*-+/,//{
/+-\{10,\}ANZEIGE-*+/{
c\
WERBUNG ENTSORGT
} ;# if pattern found, which is the
;# last line of the add, change it
;# to Werbung entsorgt.
d ;# delete pattern-space.
}
# remove footer in billiger
/^\*\**\*\ $/,/^$/d
# remove gmx-adds
/^####*Anzeige###*$/,/^##*#$/{ ;# // repeats last regexp
//{ ;# if // found
N ;# append next line to pattern-buffer
/\n$/c\
WERBUNG ENTSORGT
} ;# if a \n is at the end of pattern-space
;# change it to WERBUNG ENTSORGT
d ;# delete pattern-space
}
|
:0fw: * ^From:.*\<gmxred@gmx\.net\>.* | sed -f $HOME/scripts/sed/deladds.sed >> /home/tibit/mail/.IN/gmx |
| Mail to HTML |
|---|
This script converts emails to HTML which is quite nice for printing. Note that this is not written by me, just modified.
URL: mail2html.sed
| Pine adresses to vim |
|---|
I use pine as my mailclient
and Vim as my editor to write the mail.
I wanted to use the email addresses defined in pine's .addressbook file as abbrevations in Vim.
The following script generates these abbrevations of the following form: mm<NICKNAME>
URL: pine_addr_2_vim_ab.sed
# Format .addressbook to vim abbrevations
:redo; # Define label redo
$s/\([^ ]*\) [^ ]* \([^ ]*\).*/ab mm\1 \2\3/
N;
/\n /!{
s/\([^ ]*\) [^ ]* \([^ ]*\)[^\n]*\(\n\)/ab mm\1 \2\3/
P
D
}
s/\n//g
s/ *//g
b redo;
|
| Callerid to Vbox |
|---|
Generates ISDN callerid.conf entries to the vbox form. WARNING: adjust the dialing prefix.
/^#/d
/^$/d
/^ZONE.*/d
/^INTERFACE.*/d
/^\[MSN\]/{
N
N
s/^\[MSN\]\nNUMBER\ *=\ *//
s/ALIAS\ *=\ *//
s/\n/ - /
s/^+49//
s/^+//
/^[0-9]\{8,\}/!{
/^711/!s/^/711/
# ^^^ ^^^ Anpassen
}
s/_/ /g
}
|
| Indexhtml |
|---|
A pretty long script which generates an index of links of an HTML file.
I recently recognized when you print a website you can't click on the links anymore ;-)
I use it as a printing filter for the lpr. Maybe sed complains about line 76; just use an different
separator.
URL: indexhtml.sed
#!/bin/sed -f
# Thu May 18 12:43:45 CEST 2000 by tilmann@bitterberg.de
#
# Description:
# Creates an index of links from a HTML file
# Does something similar like lynx -force_html -dump but
# leaves the document html (generate an index of links)
#
# Example: Input
# <HTML><HEAD></HEAD><BODY>
# foo1 <a Href="http://link.org">Click here</a> foo2
# </BODY></HTML>
#
# Output:
# <HTML><HEAD></HEAD><BODY>
# foo1 <a Href="http://link.org">[1] Click here</a> foo2
# <hr>[1] http://link.org<br>
# </BODY></HTML>
#
# NOTE:
# 1) Will break at links like <A
# HREF
# 2) Will only handle a fixed number of links (500 right now)
# TODO:
# - Remove limits mentioned above
# - let it handle weird HTML syntax
1{
# Put numbers in holdspace at first line
x
s/^/ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 \
27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 \
52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 \
77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 \
101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 \
120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 \
139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 \
158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 \
177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 \
196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 \
215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 \
234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 \
253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 \
272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 \
291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 \
310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 \
329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 \
348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 \
367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 \
386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 \
405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 \
424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 \
443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 \
462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 \
481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 \
500/
# I don't like too long lines, thats why
s/\n//g
s/ */ /g
x
}
# Start at line 1
# Sometimes you only want to start from a pattern, so replace
# '1' with /PATTERN/
1,${
/[Aa] *[Hh][Rr][Ee][Ff] *= *"[^#]/{; # don't look at internal links
G; # Get the numbers
:loop; # there may be multiple links per line, so loop
# the ||||| is used as a marker.
# We now have: foo1 <a href="blah.html"> foo2\n 1 2 3 4 .. 500
# using newline as separator to the 's' command and 'I' for casei
s
\(a *href\) *= *\("\([^"]\+\)"[^>]*>\)\([^\n]*\(\n\)\) \([^ ]*\)\(.*$\)
\1|||||=\2[\6] \4\7\5[\6] \3<br>
I
#|----1----| |----------2---------||-------4------| |---6---||--7--|
# |---3----| |--5-|
# Field Contains:
# \1 a href
# \2 the link text up to the closing >
# \3 the link itself (http://foo.com)
# \4 the rest of the input line
# \5 a newline (\n)
# \6 the number we would like to use
# \7 everything up to the end of patternspace
#
# Now the line looks like:
# foo1 <a href|||||="blah.html">[1] foo2\n 2 3 4 .. 500\n[1] blah.html<br>
t loop; # look if there is another link in that line
s/|||||//g; # delete marker
h; # save how many numbers are used
s/\n.*//; # "restore" the original line
x
s/[^\n]*\n//
x
}
}
# Just before the </body> insert index
/<\/[Bb][Oo][Dd][Yy]>/{
x; # insert saved stuff
s/[^\n]*\n//; # delete unused numbers
s/^/<hr>/
G
}
|
| Diff(1) to HTML |
|---|
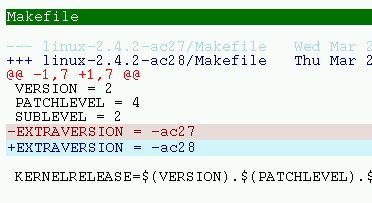
You can use it to generate nice looking pages of diff output text ("patches"). I have only tried
with unified diff's since they are the only ones I use anyway. Here is a small
screenshot. The script relies on the external utility `expand(1)'
which convert tabs to spaces and should be found on any system.
URL: diffhtml.sed
#!/bin/sh
#
# Beautifies the output of diff -Nur to the HTML format
# needs the expand utility to convert tabs to spaces, to preserve
# identation. Output HTML Code is pretty worse i think and the
# colors suck somehow
#
# Sat Apr 14 21:59:36 CEST 2001
# by Tilmann Bitterberg
expand |
sed '
s/>/\>/g; s/</\</g
s|ü|\ü|g; s|Ü|\Ü|g; s|ä|\ä|g
s|Ä|\Ä|g; s|ö|\ö|g; s|Ö|\Ö|g
s|ß|\ß|g
s/^+$/+ /
s/^-$/- /
s/^$/ /
/^[-+]/!s/$/<BR>/
1i\
<HTML><HEAD></HEAD><BODY bgcolor=white>
/^diff /{i\
<P>
s|[^/]*/||
s| .*||
s|.*|<font color=white><TT>&</TT></FONT>|
s|.*|<table border=0 cellspacing=0 width=100% bgcolor=#057205>\
<TR><TD>&</TD></TR></TABLE><P>|
}
# Could be done in one line
/^@@ /{
s|^@@|<font color=red><TT>@@|
s|$|</TT></FONT>|
}
\|^---|s|.*|<TT><font color=lightblue>&</FONT></TT><BR>|
\|^+++|s|.*|<TT><font color=darkblue>&</FONT></TT><BR>|
# Take care of removed lines
/^-[^-]/{i\
<table border=0 cellspacing=0 width=100% bgcolor=#eddcdc><TR><TD>\
<TT><FONT color=darkred>
:a
N
s/\n-/||||/
ta
h
s/.*\n//
/<BR>$/!s/$/<BR>/
x
s/\(.*\)\n[^\n]*$/\1/
s/||||/<BR>\
-/g
:space1
/ /{
s| |\ |
bspace1
}
s|$|</FONT></TT></TD></TR></TABLE>|p
x
}
# Take care of added lines
/^+[^+]/{i\
<table border=0 cellspacing=0 width=100% bgcolor=#dbf7ff><TR><TD>\
<TT><FONT color=darkblue>
:b
N
s/\n+/||||/
tb
h
s/.*\n//
/<BR>$/!s/$/<BR>/
x
s/\(.*\)\n[^\n]*$/\1/
s/||||/<BR>\
+/g
:space2
/ /{
s| |\ |
bspace2
}
s|$|</FONT></TT></TD></TR></TABLE>|p
x
}
# We need to do this, because we only want the spaces at the beginning
:c
/^Ä\+[^ ][-_A-Za-z0-9]/bend
s/^\(Ä*\) /\1Ä/
tc
:end
s/Ä/\ /g
/^ /{
s|^|<TT>|
s|$|</TT>|
}
:space3
/ /{
s| |\ |
bspace3
}
$a\
</PRE></BODY></HTML>
' # sed done
|
top
© 2001 Tilmann Bitterberg,
tilmann@bitterberg.de